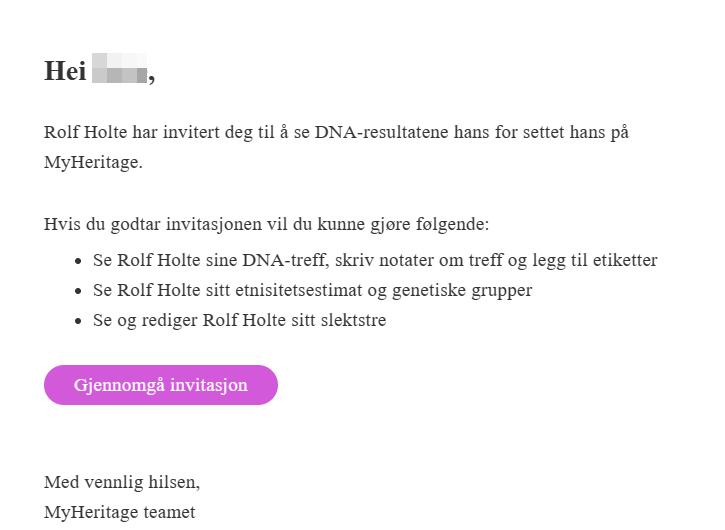
MyHeritage har nettopp lansert en mulighet for brukere å få hjelp av eksperter i eller uten for familien. Den du inviterer inn får begrenset tilgang til dine data. Her er fremgangsmåten for å få hjelp. Du kan bare dele med -1- person
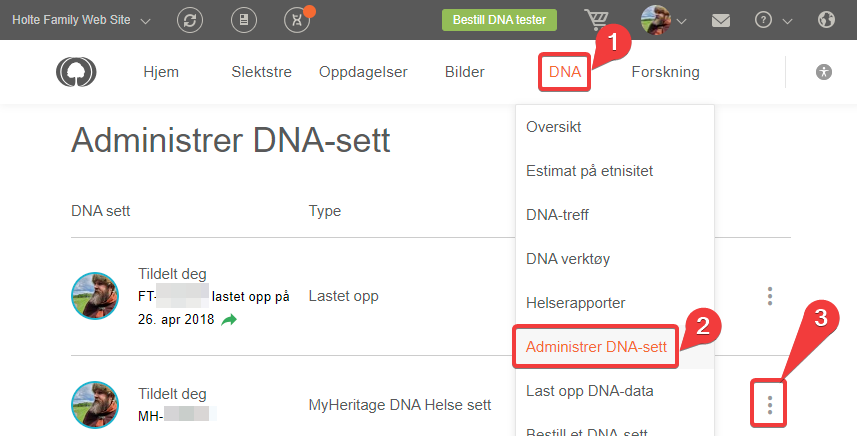
Administrer DNA-sett
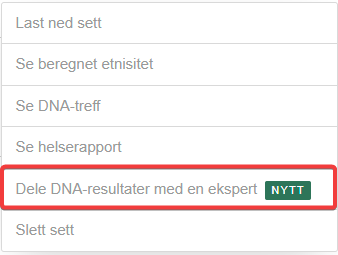
Finn de tre prikkene på høyre side av det DNA-settet du vil dele. Via denne kan du gjøre en rekke ting med ditt DNA. Dele DNA-rsultater med en ekspert er noe nytt, og du kan bare dele dine resultater med -1- hjelper (DNA ekspert)
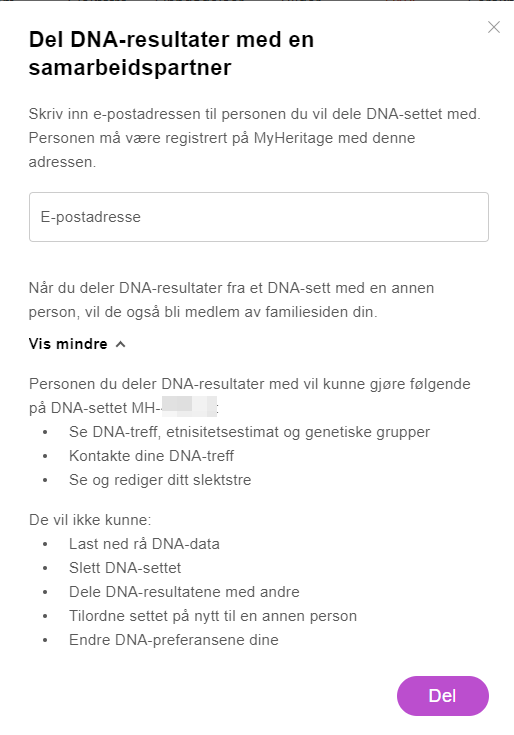
Du trenger bare epost adressen til en din hjelper (denne må ha en konto hos MyHeritage, usikker på hva som skjer om denne ikke har betalt abonnement)
Den du dele ditt DNA vil IKKE kunne:
Laste ned ditt dna (resultatfil med ACGT verdier i ulike posisjoner)
slette ditt DNA
Dele ditt DNA videre
Endre på hvilken person DNA skal vær tilknyttet
Endre på DNA preferanser
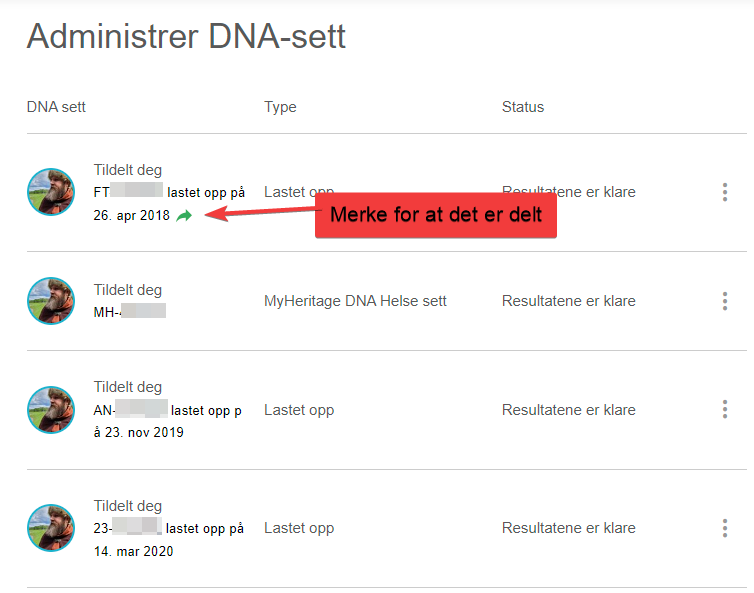
Etterpå får du en bekreftelse på skjermen:
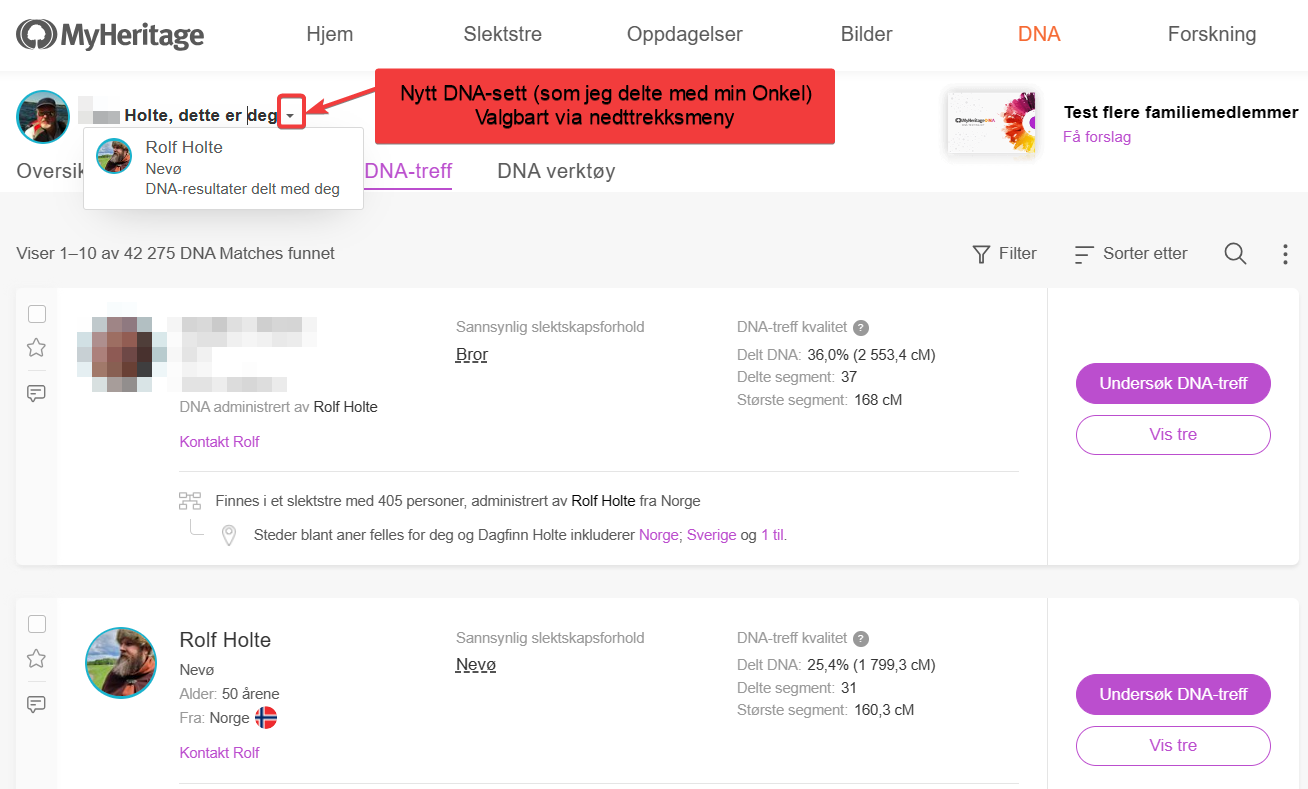
NB. Man kan se hvilke DNA-sett som er delt under administrer dna-sett
Hva får din hjelper?
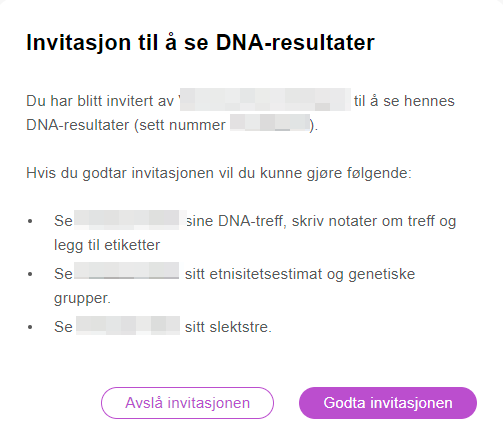
En epost hvor man kan godkjenne, eller avvise invitasjonen., som dukker opp etter man trykker gjennomgå invitasjon.
Godta/avvis invitasjon:
Man får også automastisk tilgang til slektstre hos den som har gitt deg tilgang til sitt DNA. Viktig å forstå hvilket tre man er i og sjekke tilganger for redigering av trær. Pass på å avtale hvorvidt man skal redigere treet til vedkommende eller ikke.
Jeg personlig har funnet ut at jeg bygger eget tre på min egen konto for de jeg hjelpe så jeg har 100% kontroll på hva jeg gjør.Treet kan deles med person/familien til den som trenger hjelp
Andre ting å legge merke til.
Notater som du skriver blir synlig for deg, ikke den du hjelper.
Hvor sannsynlig er det for at for at ett segment på 25 cM overlever 100, 200, 300, 400 år? Mange tror at om man deler dna over 7 cM så skal man kunne finne fellesopphav innen 5-6 generasjoner. Dette er en ofte uttalt utsagn med autosomalt dna. man kan se 5-6 generasjoner tilbake i tid. Jeg har tidligere skrevet om Hvorfor alle slektninger ikke er dine DNA slektninger, denne sier noe om at vi mister aner
Nå ønsker jeg å forklare en annen årsak om hvorfor det av og til er vanskelig å finne felles opphav. Segmenter kan overleve ganske mange flere generasjoner enn det vi er klar over, og faktisk lengre tilbake i tid enn det vi har sikre skriftlige kilder på.
Om du du er lite interessert i hvorfor dette stemmer hopp til avsnitt: Sticky segments – Segemter som (over)lever mog se på konklusjonene
Bakgrunn
1 cM = 1% sjanse for at ett segment deler seg opp i neste generasjon, og dermed 100%-1% = 99% sjanse for at den IKKE deler seg opp.
fra definisjon på centimorgan
Det er nemlig slik at jo større segment man har arvet jo større sannsynlighet er det for at det deles opp i neste generasjon. Viktig å merke seg. Det er ikke alltid at segmenter deler seg så selv om ett segment du har fått fra farmor er på 125 cM betyr det ikke det MÅ deles seg. Over 100% betyr altså ikke at det vil dele seg.
Håper du ikke har falt av lasset ennå. Mitt poeng med dette er å vis til en side hvor du kan se på hvor sannsylig er det at ett segment på x cM overlever i y antall år.
Folk som jobber med DNA har ofte ett forhold til cM eller prosent, selv sliter jeg med prosenter fordi jeg er med kjent med betydningen av hva centiMorgan er. Definisjonen er egentlig ett må på hvor sannsynlighet er det for at i neste generasjon blir ett segment delt. Mange tror cM er ett fysisk mål som antall punkter på ett segment. faktum er at siden våre kromosomer har ulik lengde så kan antall SNP som inngår i 1 cM variere.
Har man ikke inngående kunnskap om DNA så er man ikke helt på jorde med å tenke slik du havner ikke i trøbbel med andre DNA slektsforskere.
Jeg lagde meg deretter ett regneark som gjorde at jeg kunne regne på dette, nå har Kevin akkurat sluppet en kalkulator på nett slik at alle andre kan også leke seg dette, og dermed se på fra ett matematisk ståsted. Kevins verktøy for kunnskap verktøy siden har for øyeblikket som dette skriver 2 vektøy på denne siden. Sticky segemts (Segment Recombination Calculator)
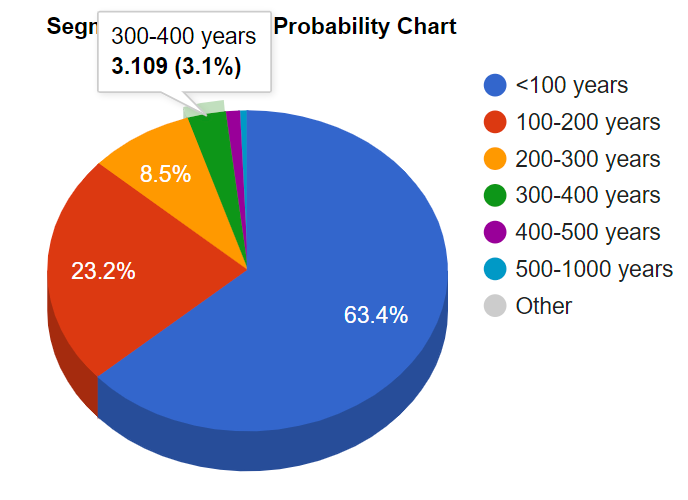
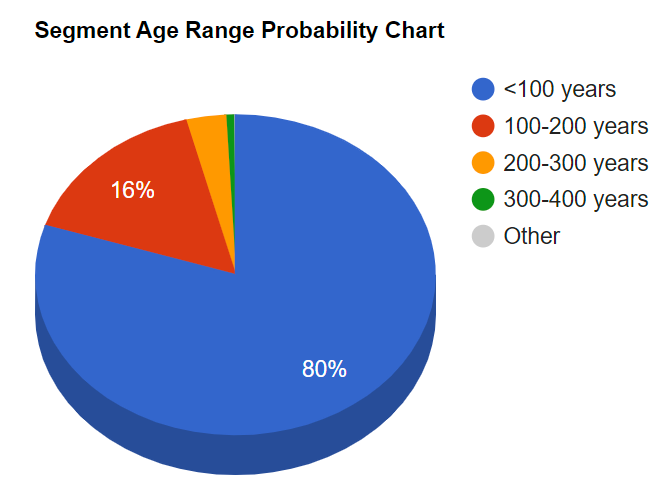
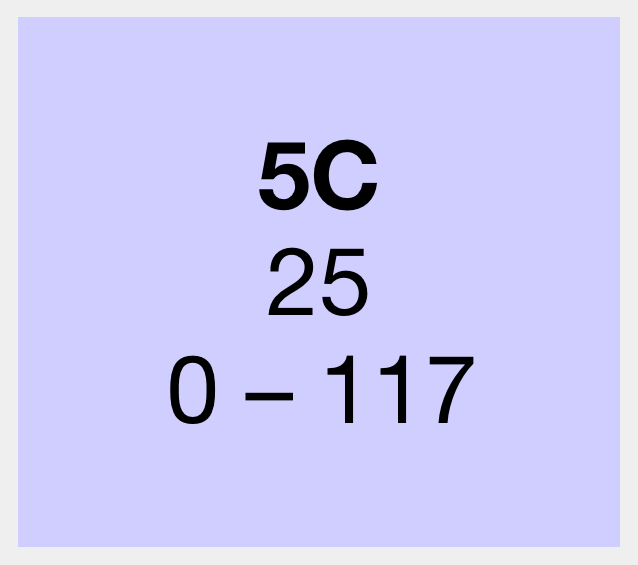
Jeg legger inn 25 cM og får følgende infomasjon:
Sannsynlighet for:
ingen rekombinasjon i neste gen: 77,78%
minst 1 rekomninasjon neste gen 22.22%
Det forsvinner (arves ikke)=sannsylighet for at det arves: 38.93%
Hvor gammelt kan dette segmentet forbli?
Det er ca 3% sjanse for at dette kan bli så gammelt som 300-400 år gammelt, eller 100-63.4=36.6 % sjannser for at det blir over 100 år gammelt!. Man kan se på dette fra mange vinkler. det er ca 1% sjanse for at det er 400-500 gammelt.
Grunnen til at du ikke finner fellesopphav kan være at det segment du har fått nedarvet er veldig gammelt, jo eldre jo mindre sannsylig. Men så lenge sannsylighet ikke er null er det mulig.
Mitt råd er som før ikke forvent å finne ut av alle slektskap du har med dine DNA traff- «Små» segmenter under 40 skal bare sees på om det er andre i samme familie som du har treff med. Jeg har DNA i 3 generasjoner som jeg ser på, ser alltid etter om det er alikevell noen nære av meg eller dna-treffet som er verdt å notere ned. barn, barnebarn av større treff gir mening, ikke fjerne 3 menninger av disse med små mengder DNA. Håper dette er forståelig
40 cm – autosomalt
Om man ser på tallene nedenfor er det 80+16=96% at ett 40 cM segment er ungre enn 200 år gammelt. Dette gir en hyggelig odds for en som leter etter felles opphav. Skulle du ikke finne det ut, kan det være over 200 år gammelt med 4%. NB andre årskaer til at man ikke finner ut av ting
NPE – non patenal/parent event = Noen har «feil» i sitt opphav
DNA segmentert er egentlig mindre
Mange i slekt er fra samme område, DNA kommer mange veier (og tilbake til generasjonene under)
Alder
Sannsynlighet (%)
<100 years
79.97%
100-200 years
16.02%
200-300 years
3.21%
300-400 years
0.64%
400-500 years
0.13%
500-1000 years
0.03%
1000-2000 years
0.00%
>2000 years
0.00%
Ansvarsfraskrivelse:
Jeg har ingen aksjer i Borland Genetics, men er en god venn med Kevin Borland. Har hjulpet han på slektforskermesser med å være en nordisktalende ambasadør for hans banebrytende verktøy innen dnarekonstruksjon.
Breaking news! Endringer i vilkårene kom 17 januar. Kommer Ancestry til å lansere opplasting av DNA under Rootstech 2024 i februar, eller vil det komme senere i år?
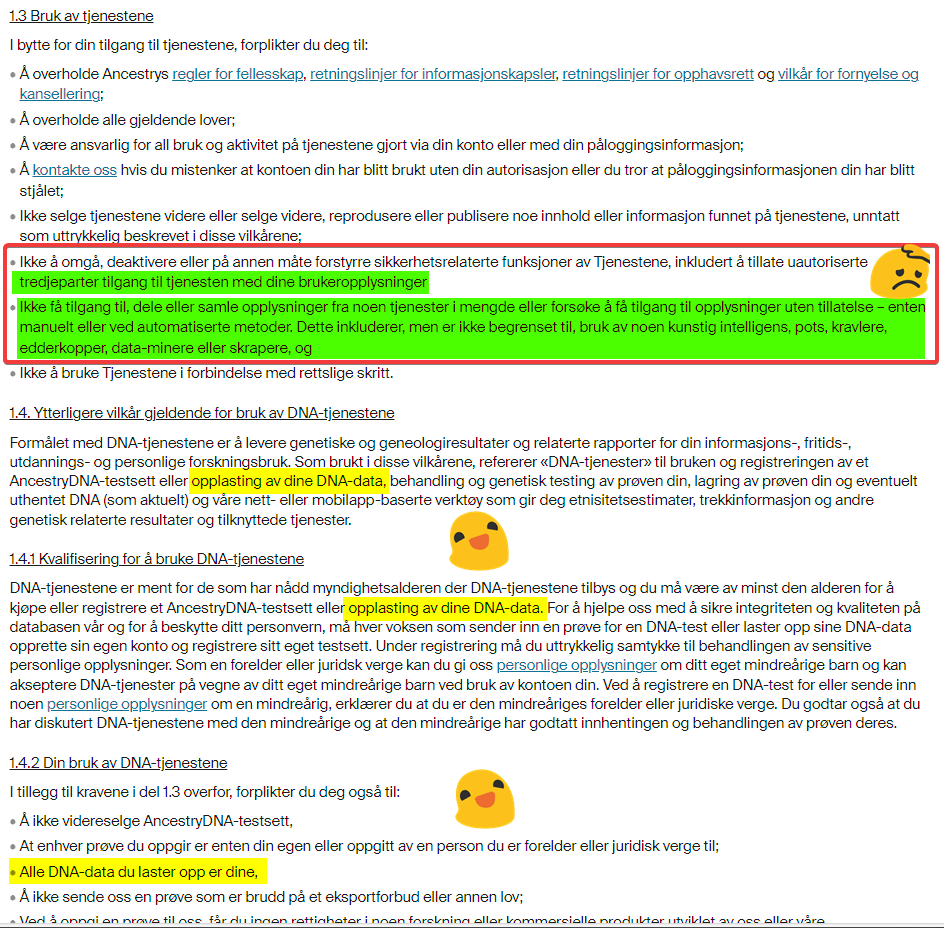
17 januar oppdaterte Ancestry sine vilkår. Her er ett lite utdrag. (Se bilde under).
Først vil jeg si at det som er innrammet med rødt og spesielt merket med grønt er noe jeg personlig er imot, fordi selv om de har funnet frem til data basert på mine data, mener jeg at eierskapet til mine data og deres analyser er mitt. De mener at det er deres, og vi som forbrukere kan ikke i praksis hente dette ut av deres systemer. Satt på spissen fordi de poengterer at også manuell utvinning ikke er lov. Om vi gjør en avskrift til Word, Excel, eller tar notater, bryter vi vilkårene. Skal man jobbe med DNA, trenger man å sitte uten å være påkoblet internett.
Det er åpenbart at overføring til eller opplasting til Ancestry kommer til å skje i nær fremtid. Hvorfor sette det inn i reviderte vilkår uten å ha dette som tilbud? Jeg tror at dette kommer til å bli avslørt under Rootstech 2024.
Så vidt jeg vet er dette noe mange har ønsket lenge. Fordelen er at folk kan ta testen sin andre steder og slippe å kjøpe ny test. Dette har sine fordeler og ulemper dog. De aller fleste selskaper tester ulike deler av DNA’et vårt. Dermed får man ulik grad av overlapp mellom testene, noe som gir større eller mindre grad av muligheter for direkte sammenligning. MyHeritage imputer data, de beregner seg frem til hva du trolig har der de mangler grunnlagsdata. En slags kvalifisert gjetning. I mange tilfeller er dekningen mellom tester godt nok, men ikke alltid. Grunnen til at selskapene har ulike versjoner er at hva de ønsker å teste, eller ikke teste, har forandret seg over tid. Har man dårlig råd, så holder det i første omgang å overføre tester der det er mulig, noe jeg har tidligere omtalt som fiskestrategien. Har man god råd og ikke mange å teste, så er det i utgangspunktet best å kjøpe tester hos alle.
– Forutsier hvordan du kan være i slekt med et DNA-treff, basert på delt DNA mengde og alder. Trolig en av de mest oversette nyhetene fra Rootstech 2023 er en ny måte å se på slektskap.
Alderforskjell og delt DNA mengde kan nå kombineres slik at når man vet alder på deg og/eller treff kan man med mye større nøyaktighet si hva slags slektskap som deles. Sannsynligheten for disse slektskapene kan også predikeres. Folk flest har også utfordringer med betegnelser som 2CR1. Den største utfordringen med disse at retningen på slektskapet er tvetydig. Ved å ta utgangpunkt i alder eliminerer man denne tvetydigheten. Kjønn er også nå en faktor slik at betegnelsene i relasjonen kommer frem.
Alle kan bruke cM explainer man trenger hverken å være medlem eller logge på
Men MyHeritage har bakt dette inn for alle som har DNA hos de. Først av alt i treff listen vil man nå se ett bedre estimat på slektskap. Faktisk de kaller ikke dette estimert slektskap lengre, men «Sannsynlig slektsskapsforhold»
Grunnen til at jeg ikke anbefaler å plukke frem cM eplainer herfra er at man kun får se oversikt med mulige slektskapsforhold går man inn på «Undersøk DNA-treff» og ser på hvilke DNA-treff du deler med treffet får man opp dette treet i tillegg.
Vis flere slektsskapsforold + diagram vises kun på side for delte dna treff (pil over)
forstå hva som ligger bak
Larry Jones, Texaner og genetisk genealog har over noen år utviklet en annen tilnærming til slektskap basert på delt DNA mengde og alder. Han startet med Ball & Pattern metoden, før han la til sannsynligeter for slektskap og kalte det cM Solver Tool. https://www.cmsolver.com/
Superenkelt forklart er «Ball & Pattern» en måte å håndtere størrelser av delt DNA. Man generaliserer hvor mye delt DNA som sendes til neste generasjon eller sett bakover i tid, hvor mye kommer fra generasjonen over dette utgjør en ball som skal virke som en rettesnor. Om man går sidelengs og nedover følger arv også samme prinsippet. Har man delt DNA mengde kan man si hvilke baller man kan havne på, som igjen er ulike former for slektskap.
CM solver utnytter aldersforkjell fra deg til andre sammen med ball and pattern. Dette utelukker i stor grad en rekke slektskap. Man kan ikke være en bestemor til ett søskenbarn om man er yngre enn den man har DNA-treff med. Men ett barnebarn til ett søskenbarn av en DNA-treff. Aldersforskjell sier noe om hvilke retninger som kan være riktig og hvilke som er umulige. Delt DNA mendge har dualitet dvs om man deler en gitt mengde dna med en person så er du enten barnebarnet eller besteforelderen.
MyHeritage sitt vitenskapsteam har sett på slektskap og aldersforskjeller i sine databaser og forbedret Larry sine sannsynligheter for slektskap basert på alder. Dermed løser de noe av utfordringen folk flest har med forskjøvet slektskap (Once-, Twice removed). De har utviklet en ny algoritme for aldersforskjell
Hvilket svar er rett?
Folk misfortår ofte dette med sannsynlighet, at noe er mer sannsynlig betyr ikke at det er mer korrekt, det er større sjanse for at det er korrekt. Forstår DU forskjellen? Det korrekte svaret kan være mindre sannsynlig. At noe er sannsynlig betyr dermed at det kan være korrekt. Når noe er usannsynlig bruker vi informasjonen til å utelukke det alternativet. De viser ikke hvilke slektskapsforhold som er umulig i sitt oppsett. Vil du vite hvilke det kan være bruk Shared cM tool.
ALLE som er sannsynlige kan være svaret, absolutt alle… med mindre du har andre forklaringer som kan utelukke.
Hvorfor virker ikke dette for meg?
Du eller den du sjekker er i slekt med mange av dine slektninger på flere måter
Du har endogamy i slekta (som er en ennå mer sammenblandet slekt)
Det er noen år siden Myheritage kjøpte Geni. Men det ser nå ut som samarbeidet har gitt resultater. Nå kan brukere kopiere data fra kilder slik man kan gjøre med record matches hos Myheritage. Det er ikke en tro kopi, men Geni’s måte å gjøre det på.
NB dette krever abonnement hos MyHeritage for å virke. Har du komplett eller data abonnement kan du bruke kilde assistenten
Man velger hvilken informasjon man vil kopiere over fra kilden. Det er en ting man bør være klar over. Geni har ganske strenge krav til stedsinformasjon. Er stedsnavnet skrevet på en måte som er utdatert idag, må du manuelt legge det til. Fullstendig gjennomgang av muligheter finnes på bloggen til Geni dog på engelsk
Myheritage har innført «Theory of Family Relativity™» (TOFR) og skal man jobbe systematisk med listen kunne det vært kjekt å få tilsendt bare disse. Denne muligheten finnes ikke så jeg har lagd en måte å automatisere dette med en teknikk som kalles webscraping. PS Teoriene er basert på smart macthes og delt dna, og er bare forslag. Siden disse kan være feil er det lurt å undersøke om denne «jukse-metoden» har noe hold. «Juks» siden de bruker Big-data for å forsøke å låse slektsgåten for deg automagisk, for vil vi slektsforskere egentlig få fasiten utlevert?
NB ADVARSEL OG ANSVARSFRAKRIVELSE!
Oppskriften er teknisk og jeg kommer ikke til å drive mye gratis support for at du skal få dette til om du ikke forstår min oppskrift. Pga personvern og generell datasikkerhet kan jeg heller ikke teste dine data for å finne feil, eller optimalisere uthentingen for deg. Jeg tar heller ikke noe ansvar for problemer du kan havne i ved feilbruk. Ikke hent ut listen hundre ganger om dagen, du kan bli utestengt fra MyHeritage i kortere eller lengre tid hvis du bombarderer websiden deres. med forespørsler.... Du er herved advart.
Forarbeid
Først må du ha en nettleser som støtter bruk av chrome utvidelser. Dette kan være Chrome, Microsoft Edge, Opera eller andre. (Finnes også en firefox add-on for dere som bruker firefox)
Gå til Webscraper.io og last installer utvidelsen (se bilde under)
Bilde 1 – Installer chrome utvidelse
Tilpassning av definisjonsfilen
Man kan lage sine egne JSON «definisjonsfiler» for uthenting. Jeg brukte litt tid på å lære dette og hvordan man kan redigere disse enklere. Det er lett å gjøre noe feil og jeg startet pånytt mange ganger før jeg fant en enklere måte, nemlig redigere i selve definisjonsfilen. Det er lett å rote til denne om man er unøyaktig. For å spare deg for å lære hele «opplegget» skal jeg forsøke å fortelle om det viktigste man bør kunne endre. NB Hele teksten nedenfor må kopieres og redigeres før du bruker den.
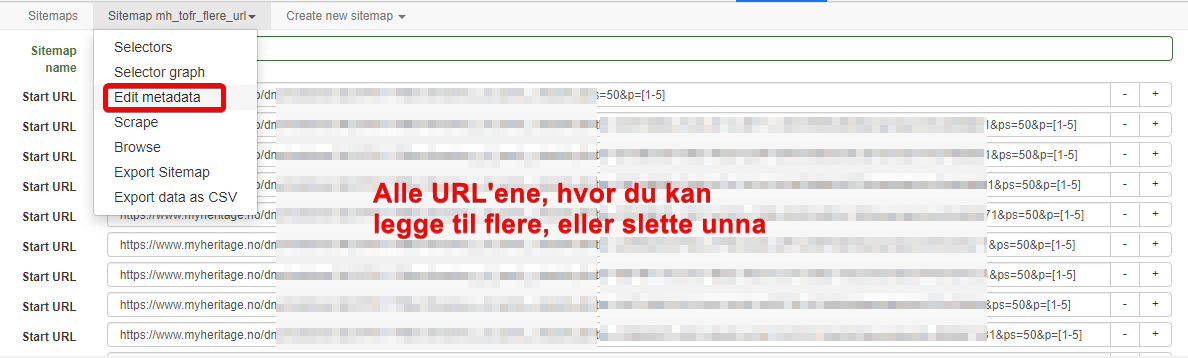
Tekst i hermetegn blir navnet på navnet på scraperen (uthenteren) som også blir navnet på csv fila som lages og kan importeres i Excel. Navnet kan endres når man importerer definisjonsfila, eller med «edit metadata» NB Navnet må skrives i små bokstaver
Start URL
Har man flere kit kan man velge å ha en uthenting for hvert kit til hver sin fil, eller hente alle etterhverandre til en fil. Skal du hente flere må hver URL være omsluttet av hermetegn og adskilles med komma. Har du bare ett kit fjern komma og «URL2».
"startUrl":["URL1","URL2"]
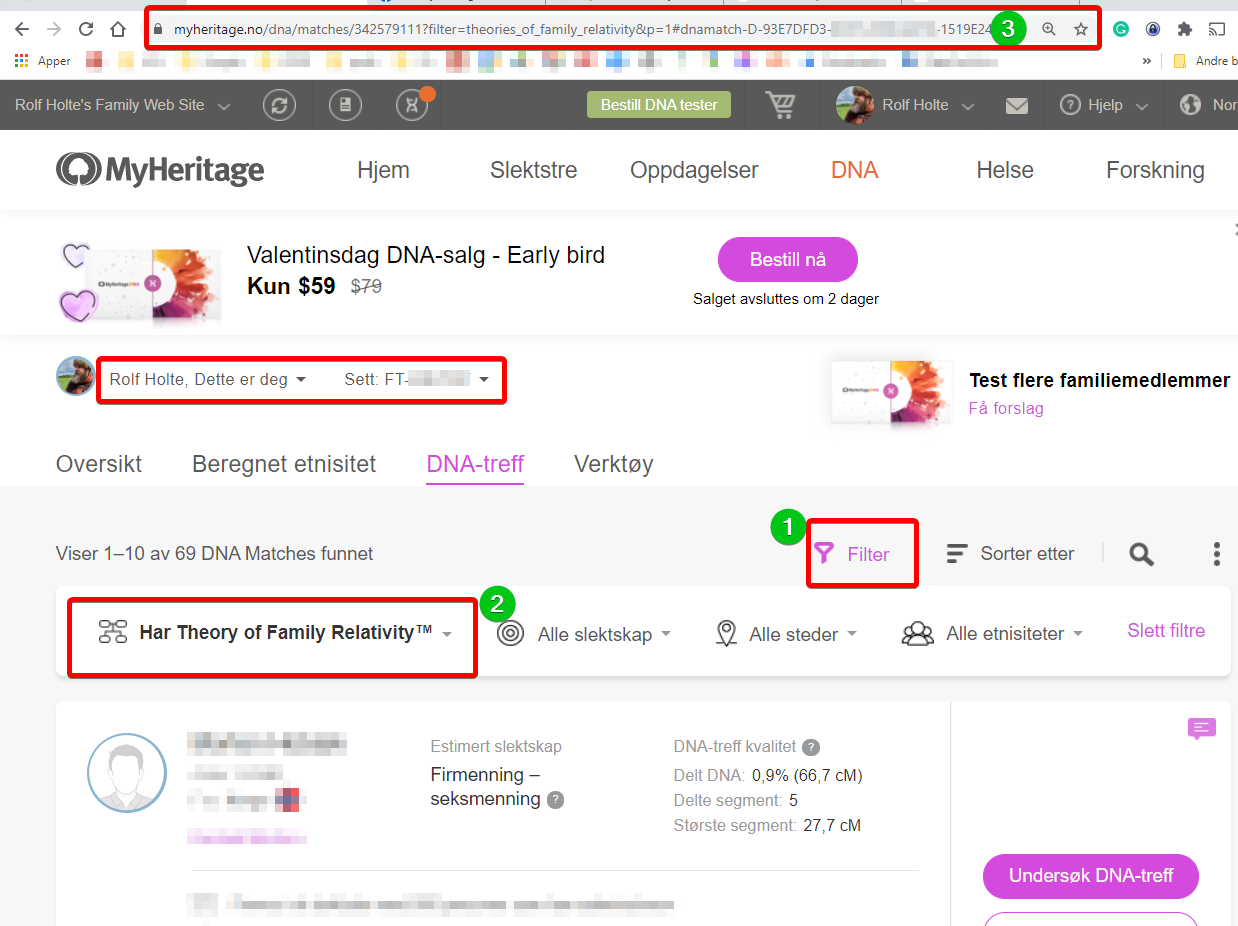
For å finne din TOFR URL må du gå til dine DNA treff og velge filter (Tredetaljer): Har Theory of Family Realtivity, Deretter må du opp øverst i nettleser og kopiere URL. Punkt 3 i bilde under. (Jeg har flere kit på min profil så jeg kan i tillegg til å velge person, kan jeg velge hvilket av disse jeg skal se på. MH kaller disse for sett på norsk)
NB! Din URL kan ha færre eller flere bestandsdeler. Forklaring på oppbygging er under. Hvert punkt tar opp ulike deler og dens betydning:
Tall etter /matches/ – Er ditt nummer
? – alt etter spørsmålstegnet er paramtre
& – standard skilletegn for parametre
# – spesialtegn (anker) som må være foran dna-kit-nummer
filter=theories_of_family_relativity – filter for å få frem teoriene
&p=1 – Paginering start side er 1. Opprinnelig vises 10 treff pr side. Om man skriver &p=[1-10] skal man i teorien hoppe frem stegvis 1 side av gangen tom side 10. (10×10 = 100 treff skal hentes ut)
&ps=25 – parameter for visninger pr side – betyr at det skal vises 25 treff av gangen.
#dnamatch-D-93E7DFD3-8F57-4190-xxxx….2-88D386A19998 – Har du flere kit pr person må hver kit spesifiseres spesifikt utover den «første» i sett listen.
Rediger "startUrl":["URL1","URL2"] til noe ala "startUrl":["https://www.myheritage.no/dna/matches/342579121?filter=theories_of_family_relativity&ps=25&p=[1-3]"] Du kan ha flere TOFR url'er adskilt av komma
Når jeg testet dette fikk jeg først ikke til å hente ut alle om jeg valgte paginering, ei heller om jeg valgte å øke antall pr side som visningsparameter. Jeg fikk noen ganger bare noen få av alle mine kit. Ved å øke tidsparameter fra 2.000 ms til 20.000 ms under kjøring fikk til slutt med alt. Det kan hende at paginering hadde virket om jeg økte tiden til 10.000 ms (10 sek). Jeg brukte bare &ps=150 fordi jeg hadde på det meste 130 TOFR. Lek derfor litt med hva som passer for deg.
Selectors
Alle elementer som opplegget består av er basert på ulke valgte elementer på html siden. For de teknisk interesserte er dette css basert. feks div.navn betyr velg innholdet mellom <div class=navn»>…</div>. Merknad: Dersom klassen har navn som har mellomrom i seg er det siste leddet som skal brukes fordi » div.navn tekst» betyr <div class=»navn»><tekst>…</tekst></div> og ikke <div class=»navn tekst»>.
Import SITEMAP (definisjonsfila)
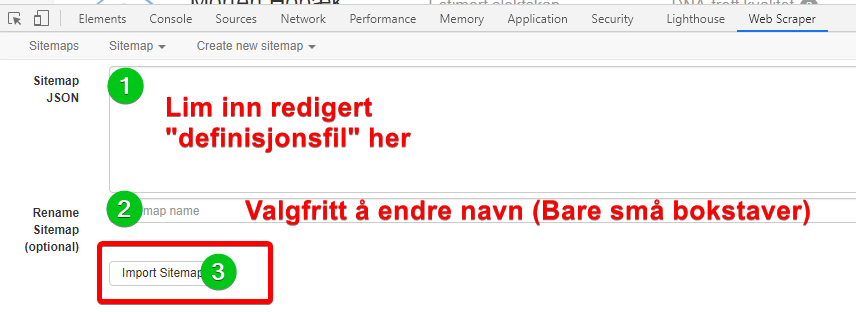
Aktiver utvidelsen ved å trykke F12 (jeg har valgt å ha vise disse nederst på siden). Klikk på fane «Web scraper» som vis i bilde nedenfor. Står det ikke Web Scraper har du enten ikke installert tillegget for Chrome, eller så har du ikke aktivert denne.
Klikk på Create new Sitemap, Velg Import Sitemap
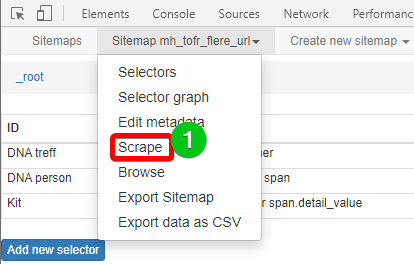
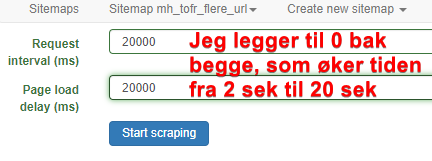
Scrape – Uthenting
Se bilde over for hvor du starter innhenting av data. Etter at menypunktet er trykt så kommer en særdeles viktig del. Du skal angi hvor lenge nettleser skal vente på data og hvor lenge nettsiden skal få lov til å bruke før neste side hentes. Jeg la til 0 bak slik at tiden økte fra 2 sekunder til 20. Bedre å vente noen ekstra sekunder enn å ikke få med seg data.
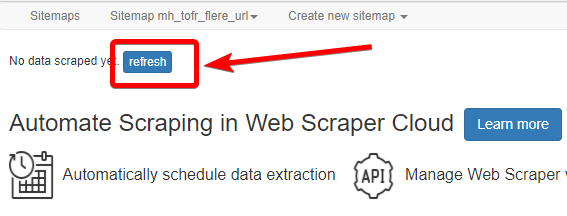
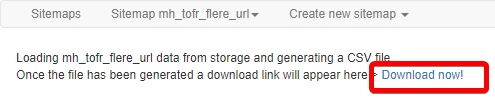
En nettleser åpnes seg og du kan følge med på at den åpner nettsidene og går videre. IKKE LUKK DENNE ved å X’e den ut. Den lukker seg selv når den er ferdig. For å se hva som ble hentet ut, trykker du på refresh knappen
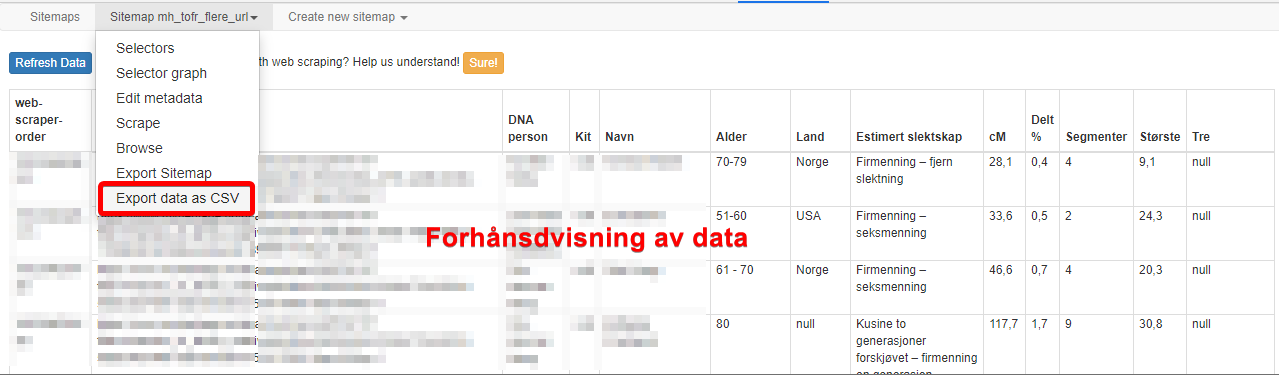
For å lagre må man velge «export data as csv». Deretter kommer en lenke du må trykke på. CSV filen lastes ved å trykke på lenken «Download now»
Virket ikke? – Juster og prøv igjen
Ble det noen krøll? Test deg frem med å øke antall sekunder som scraper skal vente. Om du vil endre på noen av parameterene og prøve igjen kan dette gjøres ved å velge «edit metadata»
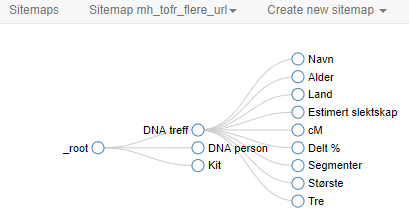
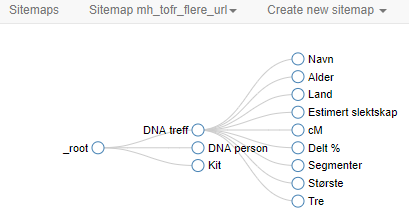
Selector Graph viser logikken på ulike steg den bruker for å hente frem data.
Selector Graph: Grafisk oversikt på opplegget
Excel
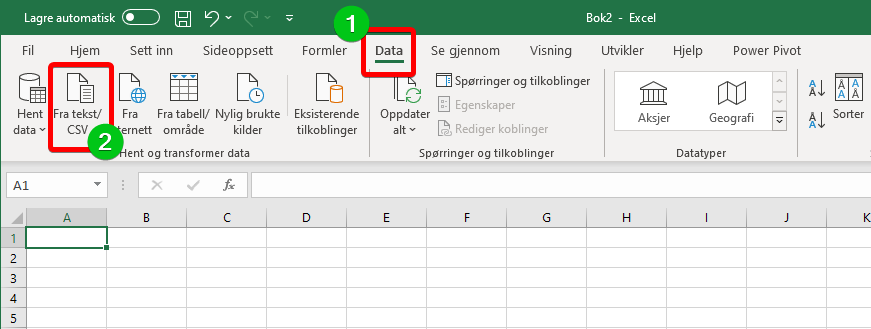
Norsk versjon dessverre ikke lese csv filer direkte fordi vi i Norge og USA bruker komma og semikolon ulikt. Den enkleste måte å hente inn CSV filer er å bruke en import funksjon i Excel for CSV filer som ligger under menypunkt Data. Under importen kan man velge å manipulere data / fjerne kolonner som du ikke trenger. Dette viser jeg ikke. Bruksanvisningen er for lang allerede
This is an english version of something I wrote in Norwegian blog post about X inheritance
Mother always gives all children an X.
Father always gives Y to sons.
Father always gives X to daughters.
Son can never get X from his father. (2)
Daughter can never get Y. (1 + 2)
Fathers always pass on their mother’s X to daughters. (1 + 3)
X is inherited from any parent. (1 + 3)
X is never inherited via two males in line (2)
X is always inherited through female lines. (1)
Father’s X is always passed down unchanged to daughters. (3+4+6 *)
Father’s Y is always passed down unchanged to sons. (2 *)
Females most often pass their X recombined to children. (1) however, sometimes they don’t recombine their X (*)
X brakes down slowly through generations especially if it passes through male lines. Therefore, X may contain identifiable DNA several generations further back than you are used to. (10)
Grandfather’s X never moves on to grandchildren on the paternal side. (8)
Grandfather’s X is passed down on to grandchildren on the maternal side. (10)
X-DNA can be used to hypothesize if (half-)sisters have the same father or not. They will always have a 100% match on X-DNA if they have the same father. Do not always assume halfsisters have the same father unless you have other evidence (NB! Read 12 again)
Full sisters will always have a 100% match on X. (10)
Brothers with the same mother will normally always have a different X from her. (12)
Brothers with same father share same Y (2 *)
*) Recombination requires two identical chromosomes to take place. Minute changes (mutations) in DNA do occur rarely on single Y and X chromosones.
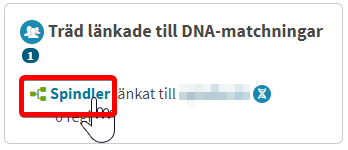
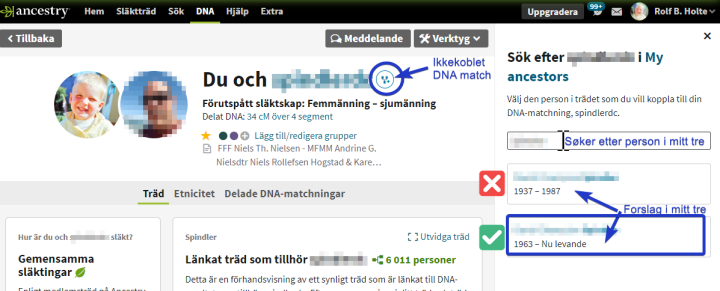
Ancestry har nettopp kommet med markering av personer i ditt tre som er en DNA match, med et eget ikon. Andre personer som har tilgang til ditt tre vil se dette merke (ikonet), men avhengig av innstillinger ellers på treet dit vil de se navnet på denne personen, eller ikke. Informasjon om levende personer er nemlig normalt skjult. Jeg skal jeg vise hvordan man kan legge til personer basert på en match.
Ancestry prøver å finne hvem som er felles ane/anepar for deg og din match. Tjenesten kalles Thrulines. NB Alle matcher har ikke en ThruLine
ThruLines™ visar hur du kan vara släkt med dina DNA-matchningar. ThruLines™ baseras på information från släktträd; de ändrar inte informationen i träd. Om informationen i ditt träd är felaktig kan du få felaktiga ThruLines™. Endast du och dem som du har inbjudit att se dina DNA-resultat kan se dina ThruLines™.
Ancestry.se – hjelp
Thrulines
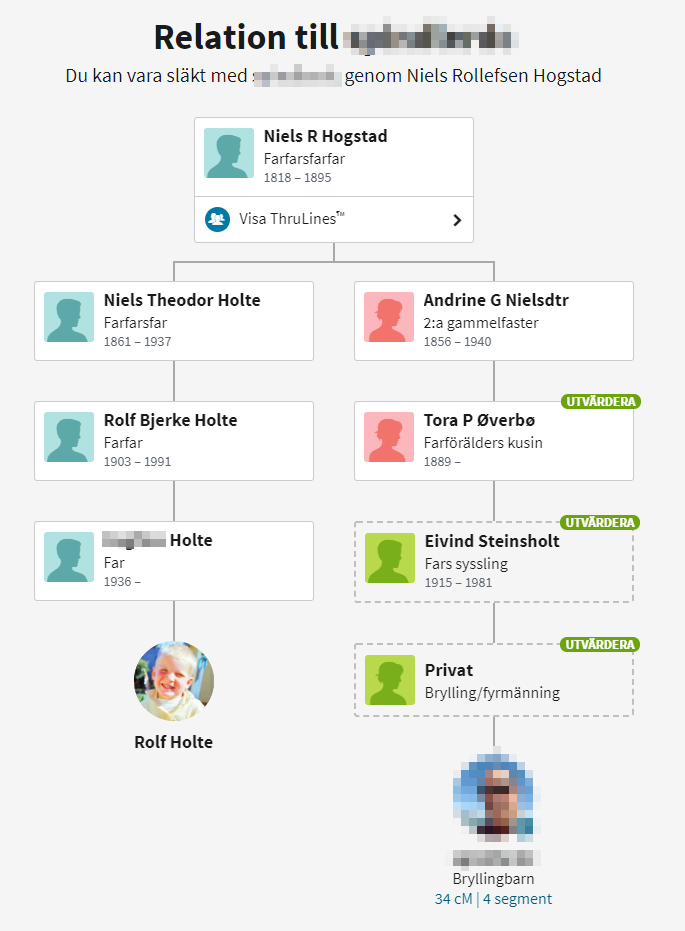
Niels Rollefsen er forøvrig «stamfar» for min Holte slekt. Han var lærer i Siljan i over 50 år
Det som er fint med Ancestry er at når man undersøker om matchen er reell eller ikke, vil de vise deg alle kildene som den tror at vil hjelpe deg å avgjøre om datane er relle eller ikke. Disse er avgrenset i tid og rom basert på informasjon som finnes i alle Ancestry medlemmers slektstrær. Noe annet som er viktig er at du kan ha ulike trær på ancestry. Hvilke av disse trær som er synlig for andre er opp til deg. Du kan feks ha ett skyggetre der hvor du putter informasjon uklarete persone inn, eller du kan legge til personer direkte i ditt «Offisielle tre». Selv har jeg forløpig bare min aner i ett og bare ett treet. Dette treet skal også inneholde alle personer de jeg deler DNA med, fordi denne nye funksjonen med merking av DNA matcher kom nettopp.
Som tidligere nevnt starter jeg med en kjent match. Matchen er den jeg fant først utav på FamilyTreeDNA. Grunn: Skjønte hvor han hørte hjemme hos meg fordi Øverbø navnet stakk seg ut. Min match bor i USA har bare en smal gren som var norsk noe som også gjør det lettere å følge denne personens aner til en felles ane.
PS Bruker alltid notatfelt til å beskrive hvordan vi er i slekt med hverandre på DNA matcher
Liten advarsel før jeg går videre.
Mange amerikanere skjønner ikke helt norske navnetradisjoner, i tillegg transkriberer «de» oftere feil når kilder tilgjengliggjøres, enn oss nordmenn. «Etternavn» henger igjen i flere generasjoner pga slike feil.
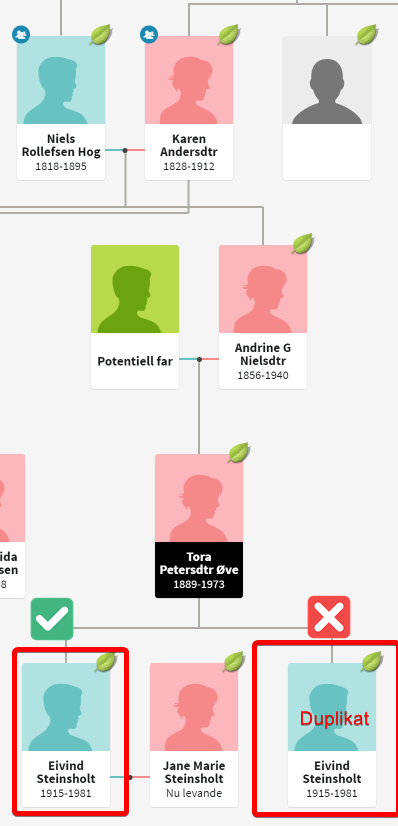
En annen fare: Er man ikke våken når man legger inn data vil man opprette flere personer enn bare 1 person. (Det er fullt mulig å slå sammen duplikater ifra profilen til en av disse, noe jeg endte opp med å gjøre..)
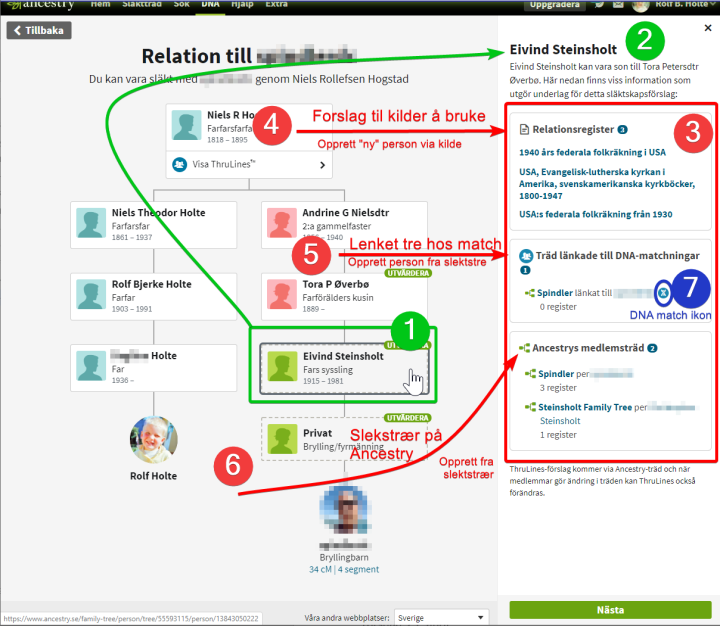
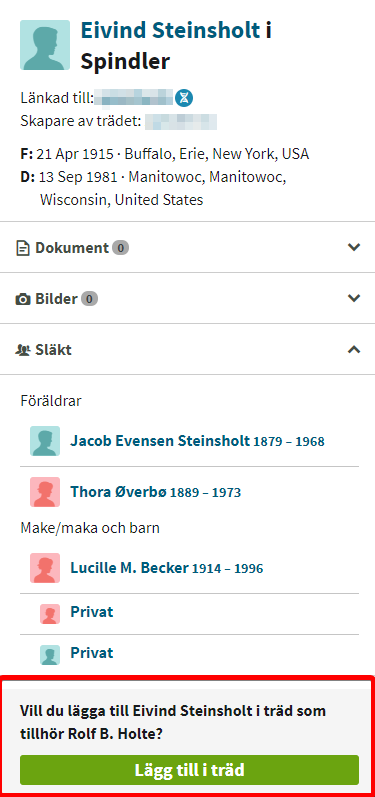
Velger å sjekke Eivind Steinsholt, klikker på han i ThruLines treet.
Dermed dukker det opp en meny i høyre marg
Under navnet er det tre bolker (4,5,6)
Alle tenklige kilder som er aktuelle for Eivind dukker opp i «Relationsregisteret». Disse er veldig viktig å sjekke og bør bukes for å avgjøre om denne personen er barn av sine foreldre. Man kan opprette person med data ifra kilden, eller..
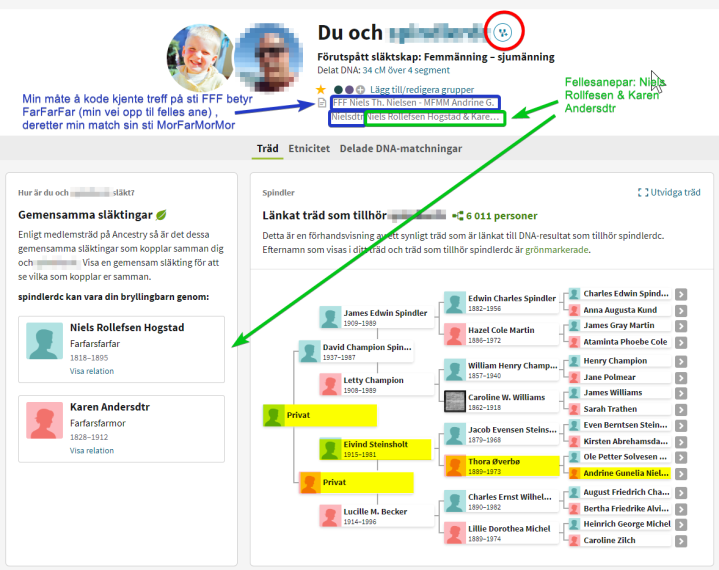
Siden jeg vet at personen er rett person vleger jeg å hente data direkte fra treet til min Match. Dermed får jeg alle data (med kilder) kopiert til mitt tre. (Bilde nedenfor)
Man kan hente data ifra andre medlemmer av ancestry. Noen kan være mer ivirige slektsforskere og du kan finne annen interresant informasjon.
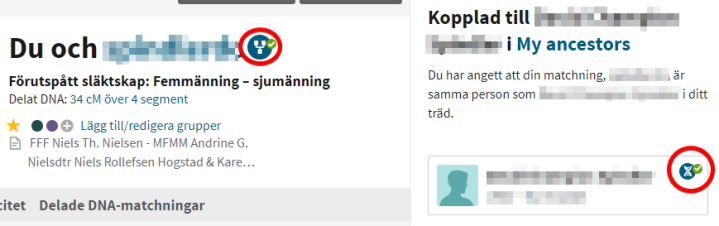
DNA match ikon
Når man kopirer informasjon fra kilde, eller annen slektsforsker velger man alltid hvor mye eller lite informasjon som skal kopieres, og man kan alltid endre alle data før man legger disse inn hos seg selv. Jeg velger å kopiere fra slektstreet til min Match, klikker på treet
I dette eksempelet er det ikke ytterlig informasjon som bilder, dokumenter så jeg velger å trykke på «Legg til tre»
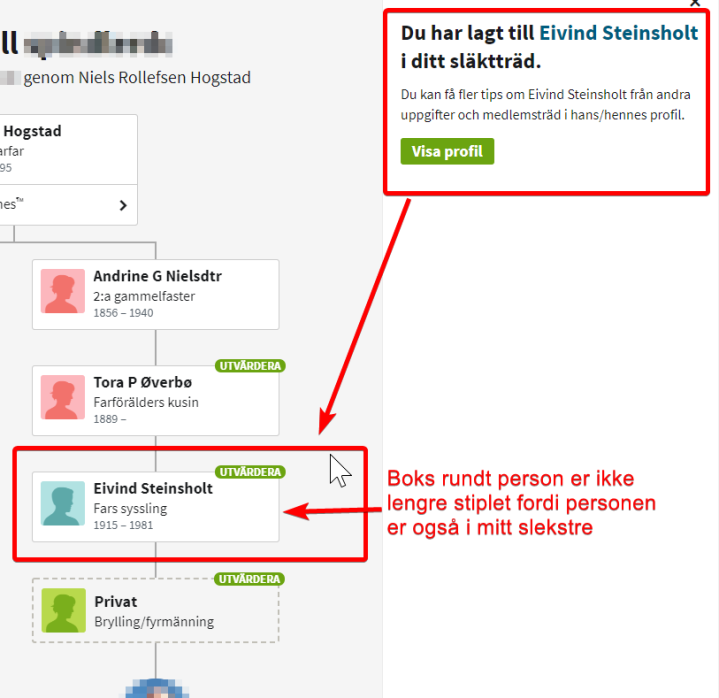
Når Eivind er lagt til i mitt slektstre forsvinner den grå boksen rundt navnet hans. Status melding øverst til høyre gir meg mulighet til å se på hva jeg har kopiert
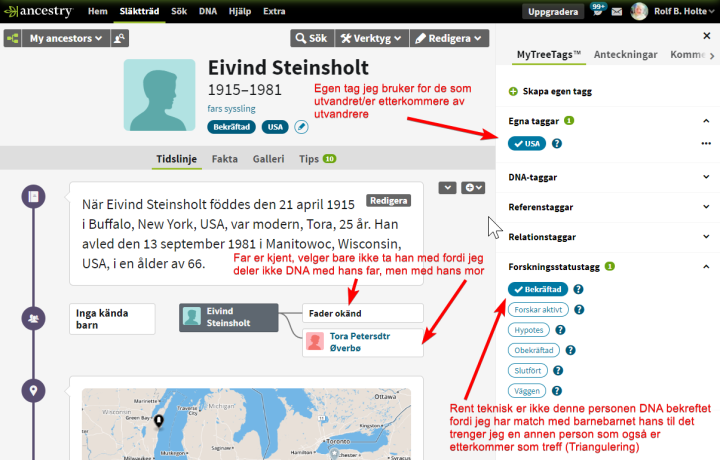
På profilsiden legger jeg på taggene USA (egendefinert) og bekreftet.
Profilside på Ancestry
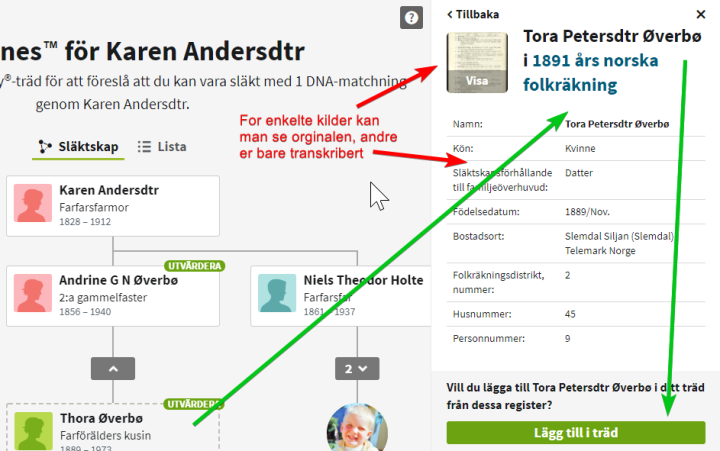
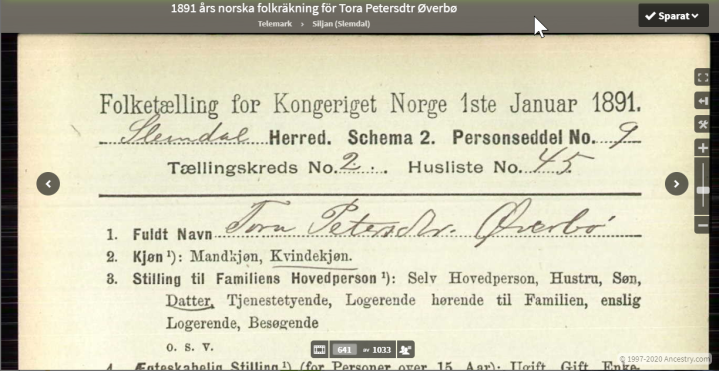
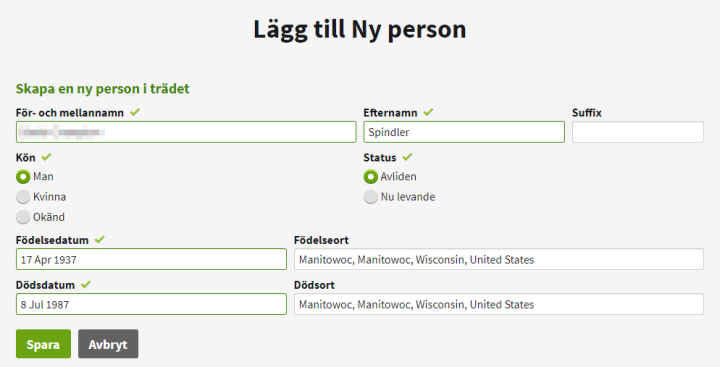
For å vise legge til med kilder byttet jeg til å se på kona til Niels Rollefsen, Karen Andersdtr. Kilder du kan granske selv er bedre for å avgjøre om slektskapet er rett, enn andre slektrær. Jeg valgte tilfeldig 1891 folketelling for Tora. Navnebruk er tema for annen dag, men følgede kan sies: Folketellinger er enten skrevet av noen i hustanden, eller person som gikk rundt og «tok» tellingen. Kirkebøker er skrevet av lærde som ofte gikk på skole i Danmark, eller er påvirket av dansker. Disse kunne finne på å fordanske norske navn. Hva er som er rett av Thora og Tora er ofte en skjønnsvurdering hvor mange faktorer tas med i betrakningen
Kildeboks (usikker på hvorfor dette er oversatt til svensk som relationsregister)
Viktig å sjekke kilder for om personen er rett, og hører hjemme hos deg eller ikke.
Når man legger til personer for man ofte spørsmål om å legge til personen, andre ganger ikke (har ikke helt forstått all logikken bak hvorfor man i noen tilfeller får dette valget og andre ganger ikke).
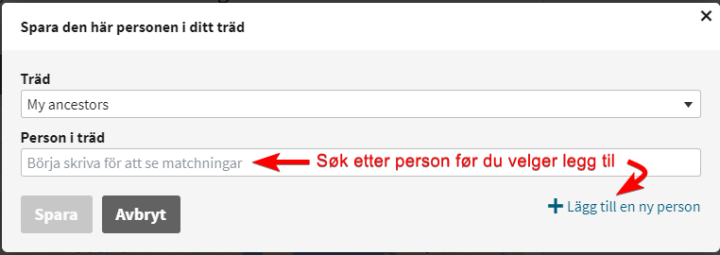
MEN Det er viktig å søke i det treet som man skal putte personen inn i (Bildenedenfor: Mitt tre heter «My ancestors», og jeg har bare ett slekttre på Ancestry… (foreløpig)
Dialog for å legg tl person i treet, Husk å søke opp navnet før du trykker «legg til»Bilde ovenfor er ikke Tora, (glemte å ta skjembilde), når man legger til personer kan man endre det som kommer opp som forslag
Siden jeg ikke var helt våken, skulle kjapt gå igjennom og ta skjermbilder oppdaget jeg ikke at jeg gjorde en feil som medførte at jeg la inn samme person med litt ulike navn, for flere personer. Men dette er løsbart
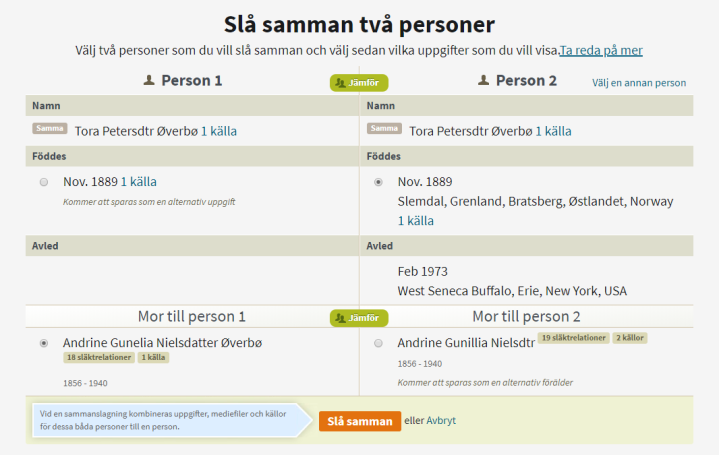
Eksempel på dupletter: Disse kan enkelt slåes sammen i Ancestry
Slå sammen: Man velger hvilke data fra hvilken person som skal stå igjen.Bilde viser at min match ikke er i mitt treMatch side hvor man kan se at match ikke er knyttet til slektstreet
Når man skal koble en match inn i treet må personen finnes i treet. I stegene foran har jeg lagt inn foreldene i rett linje opp til felles anepar. Nedenfor ser dere hvordan ikonet forandrer seg når jeg har lagt inn kobling til personen i treet.
Match er knyttet treet, ikon er mrøkt blått med grønn avkrysning
Avslutningsvis: Siden Ancestry tillater deg flere trær, så er det det treet som du kan lenket til ditt DNA som kan brukes til å lenke DNA matcher med ikonet som vist ovenfor
Den nye fjerde utgave av Shared cM Project er lansert, med nye verktøy
Siden 2015 har Blaine Bettinger hatt en nettdugnad hvor han har samlet inn data om delt DNA mengde av kjente relasjoner. Noe som har hjulpet mange å forstå hvordan man er i slekt med ett ukjent DNA treff. Leah Larkin har også bidratt med sannsynligheter, noe som også brukes i «What are the Odds» (omtalt hos meg som Hva er Oddsen)
Oppdatert versjon – Shared cM project
Siste versjon baserer seg på 60.000 kjente slektskap, noe som er en økning på 147% fra versjon 3. Dette gir økt nøyaktighet og flere detaljer. Verktøy er veldig likt som før men med følgende endringer:
Grand tante/onkel smed veid snitt, og forventet intervall
Histogramm er ett klikk unna
Du kan nå klikk på relasjoner, etthvert slektskap i blandt sannsynlighetene for å se histogram i ett nytt vindu. Histogrammer er grafer over over tallene bak. Disse kan gi deg bedre forståelse som:
Foreldre/barn bare noen få har registret delt DNA mengde under 3000cM
Minste verdi er derfor endret ned til 2376
Noen kan være det som kalles uteliggere, disse kan skyldes inntastingsfeil.
Histogrammet viser at majoriteten av data ligger mellom 3300 og 3900
Hvordan lese data: (Graf er for slektskap – Forelder). Tallverdier på x akse er gruppert, og fungerer som kurver. Tallverdier over søyler er antall registereringer i hver kurv
Om datagrunnlaget
Relasjonene
Blaine Bettinger har gjennomgått datagrunnlaget sitt og fjernet opplagte feil og uteliggere han har beskrevet dette i en rapport. Histogrammene er tatt derfra
Sannsynlighetene
Sannsynligheter er gruppert etter hvor sannsynlige de er og soteret fra høy til lav sannsynlighet.
Sannsynligheter for 1240 cM
Datagrunnlaget for disse sannsynlighetene kom fra en helt annen kilde Figur 5.2 Ancestrys fagartikkel om sammenligning (White paper on Matching). Figur viser hvor sannsynlig en spesifikk mendge delt DNA samsvarer med gitte slektskap, basert på Ancestry’s simuleringer. Noe Leah Larkin forklarer i sin blogg. Leah bearbeidet dataene videre
Disse omarbeidede data gir oss svaret på hvor sannsynlig ett 1240 cM treff er for ulike grupper. Den første gruppen Oldeforeldre, Gandtante/ grandonkel, Halv- tante/ onkel, søskenbarn, Halv niese/ nevø, Grand niese/ nevø, oldebarn har ca 74% sjanse, og netse gruppe har ca 26% sjanse (Besteforelder, Tante/ onkel, halvsøsken, niese/ nevø, Barnebarn)
Uenigheter
Siden det er to ulike datakilder og dermed ulike måter å se på disse, vil det ikke komme overaskende for noen at simulerte data og data fra nettdugnaden ikke alltid enes. Eksempelvis 400cM kan være en søskenbarn med lavt anslag av delt DNA basert på nettdugnaden, men simulerte verdier gir dette 0% sannsynlighet.
Når dette inntreffer vil verktøyet si ifra at dette er utenfor forventet sannsynlighet:
Nedenfor ser vi at for 150cM kan det være mnge slektskap som er mulig (positivt anslag 17-0,5%) Har merket disse med gult nedenfor
1C1R – (barn av ett søskenbarn) har tilnærmet 0% sannsynlighet, men fordi omfavnes innefor de grenseverdier som er mulig er de listet opp som en mulighet.
† – Gitt 99% konfidensintervall havner enkelte slekskap utenfor hva som er sannsynlig
Advarsler
De samme advarslene finnes som før, men nå er de plassert i en blå boks på høyresiden. (Disse vises ikke på mobilversjon)
Flere slektskap og endogami
Hverken shared cM project, simuleringer, nettdugnader kan håndtere flere slektskap mellom testedes aner med påfølgende anesammenfall eller edogami. Har du dette vil ikke dette verktøy være treffsikkert nok.
Gjennomsnittlige verdier vist i boksene er bare bestemt av slektskap som er kjent. For mer fjerne slektskap er det større sannsylighet at du ikke vil DNA med fjerns slektninger enn at du gjør det. Les mer om dette



























Du må være logget inn for å legge inn en kommentar.